
서브쿼리(Sub Query)란?
메인쿼리(Main Query)라는 큰 틀이 있을 때, 메인쿼리문의 내에 작성된 또 다른 쿼리문
* 예제로 이해해보자
Ex) t_emp 테이블에서 scott 보다 급여를 많이 받는 사람의 이름과 급여를 출력하라.
위 문제에 대한 쿼리문은 대략 아래와 같이 작성할 수 있다.
>> SELECT 이름, 급여 FROM t_emp WHERE 급여 > (scott의 급여);
그럼 WHERE절에 붙은 (scott의 급여)를 어떻게 얻을 수 있을까?
이름이 scott인 직원의 급여를 반환받는 쿼리문을 작성해보자.
>> SELECT 급여 FROM t_emp WHERE 이름 = 'SCOTT';
이제 우리는 저 쿼리문으로 scott의 급여를 얻을 수 있게 됐다.
그럼 이제 메인 쿼리문으로 돌아가서
WHERE절에 (scott의 급여) 대신 저 쿼리문으로 치환하기만 하면 된다.
>> SELECT 이름, 급여 FROM t_emp
WHERE 급여 > (SELECT 급여 FROM t_emp WHERE 이름 = 'SCOTT');
* 이 쿼리문의 형태가 바로 '메인쿼리 내에 서브쿼리(스캇의 급여)'이다.
서브쿼리 사용 주의사항
1. SubQuery는 연산자 오른쪽에 위치해야 하며, 반드시 괄호로 묶어야 한다.
2. 특별한 경우를 제외하고는 SubQuery절에는 Order By가 올 수 없다.
3. 단일행SubQuery인지 다중행SubQuery인지에 따라 연산자를 잘 선택해야 한다.
서브쿼리 종류
1) 단일행 서브쿼리
: 결과가 한개의 행만 나오는 서브쿼리
Ex1) t_student 테이블에서 가장 키가 큰 학생의 이름과 키를 출력하라.
① 가장 키가 큰 학생을 구해보자
= SELECT MAX(height) FROM t_student;
② 위에서 구한 학생의 이름과 키를 출력하자
= SELECT name, height FROM t_student
WHERE height = (SELECT MAX(height) FROM t_student);
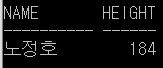
Ex2) t_professor 테이블에서 '심슨 교수와' 같은 입사일에 입사한 교수 중,
'조인형 교수'보다 급여를 적게 받는 교수의 이름과 급여, 입사일을 출력하라.
① '심슨 교수'의 입사일을 구해보자
= SELECT hiredate FROM t_professor WHERE name = '심슨';
② '조인형 교수'의 급여를 구해보자
= SELECT pay FROM t_professor WHERE name = '조인형';
③ [입사일 = '심슨교수'의 입사일] 이면서
[급여 < '조인형교수의 급여'] 인 사람의 이름과 급여 입사일을 출력해보자
= SELECT name "이름", pay "급여" , hiredate "입사일" FROM t_professor
WHERE hiredate = (SELECT hiredate FROM t_professor WHERE name = '심슨')
AND
pay < (SELECT pay FROM t_professor WHERE name = '조인형');
** 메인 쿼리 내에 서브쿼리가 2개이지만, 서브쿼리의 결과값이 하나이기 때문에 단일행서브쿼리

2) 다중행 서브쿼리
: 결과가 여러개의 행으로 나오는 서브쿼리

Ex3) t_emp2, t_dept2 테이블에서 '근무지역(t_dept2.area)'이 서울 지사인 모든 사원들의
사번(empno)과 이름(name), 부서번호(deptno)를 출력하라
① 근무지역이 서울지사인 사람들을 구해보자
= SELECT dcode FROM t_dept2 WHERE area = '서울지사';
② 위에서 구한 사람들의 사번과 이름 부서번호를 출력해보자
= SELECT empno, name, deptno FROM t_emp2
WHERE deptno IN (SELECT dcode FROM t_dept2 WHERE area = '서울지사');
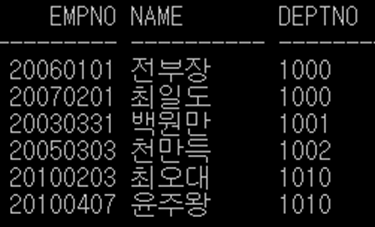
Ex4) t_emp2 테이블에서 '과장 직급의 최소급여자' 보다 급여가 높은 사람의
이름(name)과 직급(post), 급여(pay)을 출력하라. (단, 급여는 천 단위 구분 기호와 '원' 표시)
* MIN()함수를 이용해도 되지만, 이번에는 ALL 연산자를 사용해보자.
조건절이 대략 다음과 같이 작성될 수 있다
WHERE 급여 > ALL('직급이 과장인 사람')
'A > ALL (B)' 이란, B의 그 어떤 값보다 A가 큰 것일 때를 말한다.
① 따라서 '직급이 과장인 사람'을 먼저 ALL연산자에 넣어주어야 한다. 직급='과장'인 사람들을 구해보자.
= SELECT pay FROM t_emp2 WHERE post='과장';
② 위에서 구한 식을 메인쿼리의 조건절에 넣어서 과장 직급의 최소급여자보다 급여가 높은 사람들을 구해보자.
= SELECT name "이름", post "직급", pay "연봉" FROM t_emp2
WHERE pay > ALL(SELECT pay FROM t_emp2 WHERE post='과장');
③ 급여에 대해 천 단위 구분기호와 '원' 단위를 표시해보자
= SELECT name "이름", post "직급", TO_CHAR(pay, '999,999,999') "연봉 FROM t_emp2
WHERE pay > ALL(SELECT pay FROM t_emp2 WHERE post='과장');
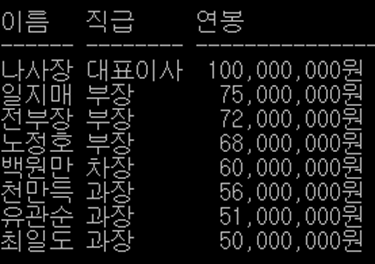
3) 다중칼럼 서브쿼리
: 결과가 여러개의 칼럼으로 나오는 서브쿼리
Ex5) t_professor, t_department 테이블에서 각 학과별로 입사일이 가장 오래된 교수의
교수번호(t_professor.profno)와 이름, 학과명(t_department.dname)을 출력하라.
(단 학과이름 순으로 오름차순 정렬)
① '학과별'로 입사일이 가장 오래된 교수들을 구해보자. (Group by 사용)
= SELECT deptno, min(hiredate) FROM t_professor GROUP BY deptno;
** 여기서 작성된 건 당연히 메인쿼리의 조건값으로 들어갈 서브쿼리문이다.
따라서 서브쿼리가 deptno, MIN(hiredate)로 이미 다중칼럼의 결과를 얻을 것임을 눈치챌 수 있다,
② '학과명'을 얻기 위해 t_department 테이블과 join해야한다.
** 단, t_professor테이블의 학과번호 값과 t_deparment의 학과번호 값이 일치하는지
확인하는 과정이 반드시 있어야 한다.
이런 조건 검사가 없으면 전혀 연관없는 학과끼리 출력될 위험이 있기 때문에 주의할 것
= SELECT p.profno "교수번호", p.name "이름",
TO_CHAR(hiredate, 'YYYY-MM-DD') "입사일", d.dname "학과명"
FROM t_professor p
JOIN t_department d
ON p.deptno = d.deptno
ORDER BY d.dname; -- 학과이름 순으로 오름차순 정렬
③ 우리는 ①에서 학과별로 가장 입사일이 오래된 교수들의 교수번호와 입사일을 얻는 서브쿼리를 구했다.
메인쿼리에 위에서 구한 서브쿼리를 조건절로 삽입하면 아래와 같다.
= SELECT p.profno "교수번호", p.name "이름",
TO_CHAR(hiredate, 'YYYY-MM-DD') "입사일", d.dname "학과명"
FROM t_professor p
JOIN t_department d
ON p.deptno = d.deptno
WHERE (p.deptno, p.hiredate)
IN (SELECT deptno, MIN(hiredate) FROM t_professor GROUP BY deptno)
ORDER BY d.dname;
** 즉, 메인쿼리에서 p.deptno과 p.hiredate에 대해서
서브쿼리(입사일이 가장 오래된 교수의 부서번호와 입사일)로 매칭되는 값을 WHERE에서 확인하고 있다.

4) 상호연관 서브쿼리
: Main Query 값을 Sub Query 에 주고 Sub Query를 수행한 후에
그 결과를 다시 Main Query 로 반환해서 수행하는 쿼리.
Ex6) t_emp2 테이블의 직원들의 직급에 대해서,
해당 직급의 '평균연봉' 보다 더 많이 받고 있거나, 평균연봉과 같은 연봉을 받고 있는 직원들의
이름과 직급, 현재 연봉을 출력하라.
** 만약 문제가 '과장직급'에 대해서만이라고 했다면, 답은 훨씬 쉬워졌을 것이다.
SELECT 이름, 직급, 급여 FROM t_emp2 WHERE 직급 = '과장' AND 급여 >= (과장직급의 평균연봉)
이처럼 '과장직급'에 대해서라고 특정하고 작성하니, 단일행 서브쿼리처럼 보인다.
그러나 문제는 모든 직원들의 모든 직급을 비교해야한다는 것이다.
이 문제는 상호연관 서브쿼리로 접근하면 해결이 가능하다.
메인쿼리와 서브쿼리가 각각 t_emp2 테이블을 가지고 있다.
즉 메인쿼리는 t_emp2 a로, 서브쿼리는 t_emp2 b를 가지는것.
그런 다음 아래 순서로 쿼리문을 작성해본다.
1) 메인쿼리에서 t_emp2 a는 특정 직원의 직급(a.post)을 서브쿼리로 넘긴다.
2) 서브쿼리에서 t_emp2 b는 a로부터 넘겨받은 그 직급(a.post)의 평균연봉(AVG(b.pay))을 a로 반환한다.
3) 다시 메인쿼리에서 특정 직원의 연봉(a.pay)과 b로부터 넘겨받은 직급의 평균 연봉AVG(b.pay)값을 비교한다.
① 일단 메인쿼리를 작성한다. a는 아무개의 직급을 가지고 있다. 이를 서브쿼리로 넘긴다.
= SELECT a.name "사원이름", a.post "직급", a.pay "급여"
FROM t_emp2 a
② 서브쿼리에서는 a로부터 아무개의 직급을 넘겨받아서 그 직급의 평균연봉을 구한다.
(**단, 평균연봉을 구할 때 b와 a의 직급이 같은지 반드시 조건문으로 체크)
= SELECT AVG(b.pay) FROM t_emp2 b WHERE a.post = b.post
③ 위에서 작성된 메인쿼리와 서브쿼리를 연결하면,
= SELECT a.name "사원이름", a.post "직급", a.pay "급여"
FROM t_emp2 a
WHERE a.pay >= (SELECT AVG(b.pay) FROM t_emp2 b WHERE a.post = b.post);
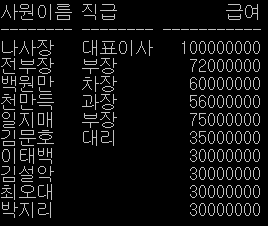
* 참고
서브쿼리는 쿼리문 내에서의 위치에 따라 명칭이 다르기도 하다.
1) SELECT 뒤에 올 때
SELECT [Sub Query문] : Scala Sub Query (스칼라 서브쿼리)
* 단, 서브쿼리의 결과가 하나의 값일 때
2) FROM 뒤에 올 때
FROM [Sub Query문] : Inline View (인라인 뷰)
3) WHERE 뒤에 올 때
WHERE [Sub Query문] : Sub Query (서브쿼리)
'SQL > Oracle' 카테고리의 다른 글
| 14_SQL Natural Join문 (1) | 2019.10.06 |
|---|---|
| 13_SQL VIEW의 사용 (0) | 2019.09.30 |
| 11_SQL JOIN문 (0) | 2019.09.26 |
| 10_SQL함수(6) 그룹함수 (0) | 2019.09.24 |
| 09_SQL함수(5) 단일행함수: 날짜함수 (0) | 2019.09.22 |
서브쿼리(Sub Query)란?
메인쿼리(Main Query)라는 큰 틀이 있을 때, 메인쿼리문의 내에 작성된 또 다른 쿼리문
* 예제로 이해해보자
Ex) t_emp 테이블에서 scott 보다 급여를 많이 받는 사람의 이름과 급여를 출력하라.
위 문제에 대한 쿼리문은 대략 아래와 같이 작성할 수 있다.
>> SELECT 이름, 급여 FROM t_emp WHERE 급여 > (scott의 급여);
그럼 WHERE절에 붙은 (scott의 급여)를 어떻게 얻을 수 있을까?
이름이 scott인 직원의 급여를 반환받는 쿼리문을 작성해보자.
>> SELECT 급여 FROM t_emp WHERE 이름 = 'SCOTT';
이제 우리는 저 쿼리문으로 scott의 급여를 얻을 수 있게 됐다.
그럼 이제 메인 쿼리문으로 돌아가서
WHERE절에 (scott의 급여) 대신 저 쿼리문으로 치환하기만 하면 된다.
>> SELECT 이름, 급여 FROM t_emp
WHERE 급여 > (SELECT 급여 FROM t_emp WHERE 이름 = 'SCOTT');
* 이 쿼리문의 형태가 바로 '메인쿼리 내에 서브쿼리(스캇의 급여)'이다.
서브쿼리 사용 주의사항
1. SubQuery는 연산자 오른쪽에 위치해야 하며, 반드시 괄호로 묶어야 한다.
2. 특별한 경우를 제외하고는 SubQuery절에는 Order By가 올 수 없다.
3. 단일행SubQuery인지 다중행SubQuery인지에 따라 연산자를 잘 선택해야 한다.
서브쿼리 종류
1) 단일행 서브쿼리
: 결과가 한개의 행만 나오는 서브쿼리
Ex1) t_student 테이블에서 가장 키가 큰 학생의 이름과 키를 출력하라.
① 가장 키가 큰 학생을 구해보자
= SELECT MAX(height) FROM t_student;
② 위에서 구한 학생의 이름과 키를 출력하자
= SELECT name, height FROM t_student
WHERE height = (SELECT MAX(height) FROM t_student);
Ex2) t_professor 테이블에서 '심슨 교수와' 같은 입사일에 입사한 교수 중,
'조인형 교수'보다 급여를 적게 받는 교수의 이름과 급여, 입사일을 출력하라.
① '심슨 교수'의 입사일을 구해보자
= SELECT hiredate FROM t_professor WHERE name = '심슨';
② '조인형 교수'의 급여를 구해보자
= SELECT pay FROM t_professor WHERE name = '조인형';
③ [입사일 = '심슨교수'의 입사일] 이면서
[급여 < '조인형교수의 급여'] 인 사람의 이름과 급여 입사일을 출력해보자
= SELECT name "이름", pay "급여" , hiredate "입사일" FROM t_professor
WHERE hiredate = (SELECT hiredate FROM t_professor WHERE name = '심슨')
AND
pay < (SELECT pay FROM t_professor WHERE name = '조인형');
** 메인 쿼리 내에 서브쿼리가 2개이지만, 서브쿼리의 결과값이 하나이기 때문에 단일행서브쿼리
2) 다중행 서브쿼리
: 결과가 여러개의 행으로 나오는 서브쿼리
Ex3) t_emp2, t_dept2 테이블에서 '근무지역(t_dept2.area)'이 서울 지사인 모든 사원들의
사번(empno)과 이름(name), 부서번호(deptno)를 출력하라
① 근무지역이 서울지사인 사람들을 구해보자
= SELECT dcode FROM t_dept2 WHERE area = '서울지사';
② 위에서 구한 사람들의 사번과 이름 부서번호를 출력해보자
= SELECT empno, name, deptno FROM t_emp2
WHERE deptno IN (SELECT dcode FROM t_dept2 WHERE area = '서울지사');
Ex4) t_emp2 테이블에서 '과장 직급의 최소급여자' 보다 급여가 높은 사람의
이름(name)과 직급(post), 급여(pay)을 출력하라. (단, 급여는 천 단위 구분 기호와 '원' 표시)
* MIN()함수를 이용해도 되지만, 이번에는 ALL 연산자를 사용해보자.
조건절이 대략 다음과 같이 작성될 수 있다
WHERE 급여 > ALL('직급이 과장인 사람')
'A > ALL (B)' 이란, B의 그 어떤 값보다 A가 큰 것일 때를 말한다.
① 따라서 '직급이 과장인 사람'을 먼저 ALL연산자에 넣어주어야 한다. 직급='과장'인 사람들을 구해보자.
= SELECT pay FROM t_emp2 WHERE post='과장';
② 위에서 구한 식을 메인쿼리의 조건절에 넣어서 과장 직급의 최소급여자보다 급여가 높은 사람들을 구해보자.
= SELECT name "이름", post "직급", pay "연봉" FROM t_emp2
WHERE pay > ALL(SELECT pay FROM t_emp2 WHERE post='과장');
③ 급여에 대해 천 단위 구분기호와 '원' 단위를 표시해보자
= SELECT name "이름", post "직급", TO_CHAR(pay, '999,999,999') "연봉 FROM t_emp2
WHERE pay > ALL(SELECT pay FROM t_emp2 WHERE post='과장');
3) 다중칼럼 서브쿼리
: 결과가 여러개의 칼럼으로 나오는 서브쿼리
Ex5) t_professor, t_department 테이블에서 각 학과별로 입사일이 가장 오래된 교수의
교수번호(t_professor.profno)와 이름, 학과명(t_department.dname)을 출력하라.
(단 학과이름 순으로 오름차순 정렬)
① '학과별'로 입사일이 가장 오래된 교수들을 구해보자. (Group by 사용)
= SELECT deptno, min(hiredate) FROM t_professor GROUP BY deptno;
** 여기서 작성된 건 당연히 메인쿼리의 조건값으로 들어갈 서브쿼리문이다.
따라서 서브쿼리가 deptno, MIN(hiredate)로 이미 다중칼럼의 결과를 얻을 것임을 눈치챌 수 있다,
② '학과명'을 얻기 위해 t_department 테이블과 join해야한다.
** 단, t_professor테이블의 학과번호 값과 t_deparment의 학과번호 값이 일치하는지
확인하는 과정이 반드시 있어야 한다.
이런 조건 검사가 없으면 전혀 연관없는 학과끼리 출력될 위험이 있기 때문에 주의할 것
= SELECT p.profno "교수번호", p.name "이름",
TO_CHAR(hiredate, 'YYYY-MM-DD') "입사일", d.dname "학과명"
FROM t_professor p
JOIN t_department d
ON p.deptno = d.deptno
ORDER BY d.dname; -- 학과이름 순으로 오름차순 정렬
③ 우리는 ①에서 학과별로 가장 입사일이 오래된 교수들의 교수번호와 입사일을 얻는 서브쿼리를 구했다.
메인쿼리에 위에서 구한 서브쿼리를 조건절로 삽입하면 아래와 같다.
= SELECT p.profno "교수번호", p.name "이름",
TO_CHAR(hiredate, 'YYYY-MM-DD') "입사일", d.dname "학과명"
FROM t_professor p
JOIN t_department d
ON p.deptno = d.deptno
WHERE (p.deptno, p.hiredate)
IN (SELECT deptno, MIN(hiredate) FROM t_professor GROUP BY deptno)
ORDER BY d.dname;
** 즉, 메인쿼리에서 p.deptno과 p.hiredate에 대해서
서브쿼리(입사일이 가장 오래된 교수의 부서번호와 입사일)로 매칭되는 값을 WHERE에서 확인하고 있다.
4) 상호연관 서브쿼리
: Main Query 값을 Sub Query 에 주고 Sub Query를 수행한 후에
그 결과를 다시 Main Query 로 반환해서 수행하는 쿼리.
Ex6) t_emp2 테이블의 직원들의 직급에 대해서,
해당 직급의 '평균연봉' 보다 더 많이 받고 있거나, 평균연봉과 같은 연봉을 받고 있는 직원들의
이름과 직급, 현재 연봉을 출력하라.
** 만약 문제가 '과장직급'에 대해서만이라고 했다면, 답은 훨씬 쉬워졌을 것이다.
SELECT 이름, 직급, 급여 FROM t_emp2 WHERE 직급 = '과장' AND 급여 >= (과장직급의 평균연봉)
이처럼 '과장직급'에 대해서라고 특정하고 작성하니, 단일행 서브쿼리처럼 보인다.
그러나 문제는 모든 직원들의 모든 직급을 비교해야한다는 것이다.
이 문제는 상호연관 서브쿼리로 접근하면 해결이 가능하다.
메인쿼리와 서브쿼리가 각각 t_emp2 테이블을 가지고 있다.
즉 메인쿼리는 t_emp2 a로, 서브쿼리는 t_emp2 b를 가지는것.
그런 다음 아래 순서로 쿼리문을 작성해본다.
1) 메인쿼리에서 t_emp2 a는 특정 직원의 직급(a.post)을 서브쿼리로 넘긴다.
2) 서브쿼리에서 t_emp2 b는 a로부터 넘겨받은 그 직급(a.post)의 평균연봉(AVG(b.pay))을 a로 반환한다.
3) 다시 메인쿼리에서 특정 직원의 연봉(a.pay)과 b로부터 넘겨받은 직급의 평균 연봉AVG(b.pay)값을 비교한다.
① 일단 메인쿼리를 작성한다. a는 아무개의 직급을 가지고 있다. 이를 서브쿼리로 넘긴다.
= SELECT a.name "사원이름", a.post "직급", a.pay "급여"
FROM t_emp2 a
② 서브쿼리에서는 a로부터 아무개의 직급을 넘겨받아서 그 직급의 평균연봉을 구한다.
(**단, 평균연봉을 구할 때 b와 a의 직급이 같은지 반드시 조건문으로 체크)
= SELECT AVG(b.pay) FROM t_emp2 b WHERE a.post = b.post
③ 위에서 작성된 메인쿼리와 서브쿼리를 연결하면,
= SELECT a.name "사원이름", a.post "직급", a.pay "급여"
FROM t_emp2 a
WHERE a.pay >= (SELECT AVG(b.pay) FROM t_emp2 b WHERE a.post = b.post);
* 참고
서브쿼리는 쿼리문 내에서의 위치에 따라 명칭이 다르기도 하다.
1) SELECT 뒤에 올 때
SELECT [Sub Query문] : Scala Sub Query (스칼라 서브쿼리)
* 단, 서브쿼리의 결과가 하나의 값일 때
2) FROM 뒤에 올 때
FROM [Sub Query문] : Inline View (인라인 뷰)
3) WHERE 뒤에 올 때
WHERE [Sub Query문] : Sub Query (서브쿼리)
'SQL > Oracle' 카테고리의 다른 글
| 14_SQL Natural Join문 (1) | 2019.10.06 |
|---|---|
| 13_SQL VIEW의 사용 (0) | 2019.09.30 |
| 11_SQL JOIN문 (0) | 2019.09.26 |
| 10_SQL함수(6) 그룹함수 (0) | 2019.09.24 |
| 09_SQL함수(5) 단일행함수: 날짜함수 (0) | 2019.09.22 |